

3월 16일, 엔비디아 GTC 2026이 열립니다. 이번 행사의 핵심 키워드는 단 하나, '루빈(Rubin)'입니다. 엔비디아의 차세대 AI 가속기 플랫폼 루빈에는 6세대 고대역폭메모리 HBM4가 탑재됩니다. 그리고 이 HBM4를 누가 더 많이, 더 빨리 공급하느냐를 놓고 삼성전자와 SK하이닉스가 사활을 건 경쟁을 벌이고 있습니다.
BofA에 따르면 2026년 글로벌 HBM 시장 규모는 전년 대비 58% 증가한 546억 달러(약 78조원)에 달할 전망입니다. 불과 3년 전 82억 달러였던 시장이 6배 넘게 커진 겁니다. 이 거대한 파이를 두고 벌어지는 전쟁의 핵심을 정리했습니다.
■ HBM 시장, 얼마나 커졌나
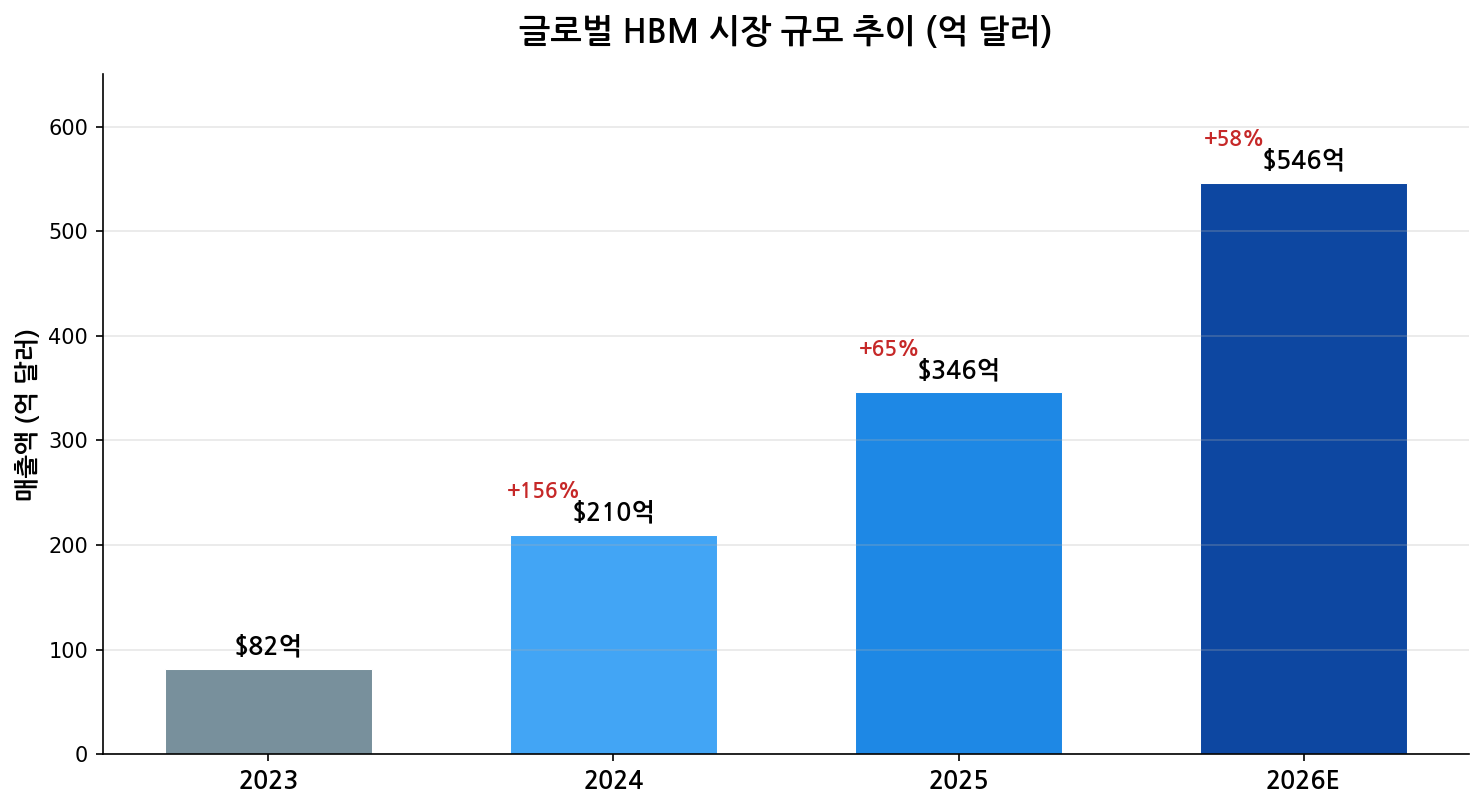
글로벌 HBM 시장 규모 추이 (출처: BofA, 단위: 억 달러)
HBM 시장의 성장세는 경이적입니다. 2023년 82억 달러에서 2024년 210억 달러로 156% 폭증했고, 2025년에는 346억 달러, 2026년에는 546억 달러로 매년 50% 이상 성장이 전망됩니다. AI 데이터센터 수요가 이 성장의 엔진입니다.
특히 주목할 점은 TSMC의 움직임입니다. TSMC는 2026년 1분기에만 450억 달러(약 65조원)의 자본투자를 승인했습니다. 연간 예산 520~560억 달러의 80%를 1분기에 몰아서 집행하는 겁니다. 이는 AI 칩 수요가 얼마나 폭발적인지를 보여주는 지표입니다. 엔비디아가 TSMC의 최대 고객으로 올라선 지금, HBM 수요는 더욱 가속화될 수밖에 없습니다.
■ HBM4, 무엇이 다른가
HBM4는 기존 HBM3E 대비 대역폭이 40% 이상 향상되고, 핀당 전송속도가 10~12Gbps에 달합니다. 엔비디아의 차세대 AI 가속기 '루빈'은 이 HBM4를 12단으로 쌓아올려 탑재합니다. 단순히 메모리가 빨라진 게 아니라, AI 모델의 학습과 추론 성능 자체를 한 단계 끌어올리는 핵심 부품인 셈입니다.
그렇다면 HBM4는 어떻게 이런 성능 도약을 이뤄냈을까요? 핵심은 크게 세 가지입니다.
첫째, 인터페이스 폭이 2배로 넓어졌습니다. HBM3E까지는 1024비트(bit) 인터페이스를 사용했지만, HBM4는 이를 2048비트로 두 배 확장했습니다. 쉽게 말해, 데이터가 지나가는 '도로'가 기존 1024차선에서 2048차선으로 넓어진 셈입니다. 독립 채널 수도 16개에서 32개로 두 배가 됐고, 각 채널에는 2개의 의사채널(pseudo-channel)이 배치되어 동시 처리 효율이 비약적으로 높아졌습니다. 덕분에 핀당 데이터 전송 속도를 무리하게 높이지 않고도 전체 대역폭을 대폭 끌어올릴 수 있었습니다.
둘째, '로직 베이스다이'의 도입이 게임체인저입니다. HBM3E까지 베이스다이(최하단 칩)는 단순히 GPU와 DRAM 사이 신호를 중계하는 '통로' 역할에 그쳤습니다. 하지만 HBM4부터는 베이스다이에 로직(연산) 기능이 탑재됩니다. 엔비디아의 요청으로, 메모리 컨트롤러, 캐시, 오류 정정, 발열 제어는 물론 일부 AI 연산까지 베이스다이에서 수행합니다. GPU가 해야 할 일의 일부를 메모리 칩이 대신 처리해주니, 시스템 전체 효율이 올라가는 구조입니다. 이 로직다이는 기존 메모리 공정이 아닌 파운드리 로직 공정(5nm~2nm)으로 제조되며, 고객사별로 기능을 맞춤 설계(커스터마이징)할 수 있다는 점이 HBM4의 가장 혁신적인 변화입니다.
셋째, 전력 효율이 크게 개선됐습니다. HBM4는 저전압 TSV(실리콘 관통 전극) 기술과 전력 분배 네트워크(PDN) 최적화를 통해 HBM3E 대비 전력 효율을 약 40% 향상시켰습니다. 또한 열저항은 10%, 방열 성능은 30% 개선되었습니다. 인터페이스를 넓히되 핀당 속도를 극단적으로 올리지 않았기 때문에, 같은 대역폭을 더 낮은 전력으로 구현할 수 있게 된 것입니다. 이는 AI 데이터센터에서 가장 민감한 이슈인 전력비용과 냉각 문제를 동시에 해결하는 설계입니다.
JEDEC은 또한 HBM4에서 명령(command)버스와 데이터(data)버스를 분리하는 설계를 채택했습니다. 기존에는 명령과 데이터가 같은 경로를 공유해 병목이 발생했지만, 이를 독립시킴으로써 다중 채널 동시 운용 시 지연시간(레이턴시)이 줄어들어 AI·HPC 워크로드 처리에 유리해졌습니다.
| 대역폭 | 1.18 TB/s | 1.65 TB/s | +40% |
| 핀당 전송속도 | 8.0 Gbps | 11.7 Gbps | +46% |
| 적층 단수 | 8단 / 12단 | 12단 / 16단 | 고단화 |
| 용량 (개당) | 24~36GB | 36~48GB | +33~50% |
| 탑재 플랫폼 | 블랙웰 (Blackwell) | 루빈 (Rubin) | 세대 전환 |
| 개당 가격 (추정) | 약 60~80만원 | 약 80~120만원 | +50% |
개당 가격이 100만원을 넘는 초고가 반도체입니다. 범용 D램과는 수익성 자체가 차원이 다릅니다. SK하이닉스의 HBM 영업이익률이 60%를 넘는다는 추정이 나올 정도입니다. 메모리 반도체 업계에 이런 마진은 전무후무한 수준입니다.
■ 삼성 vs SK하이닉스, 누가 이기고 있나
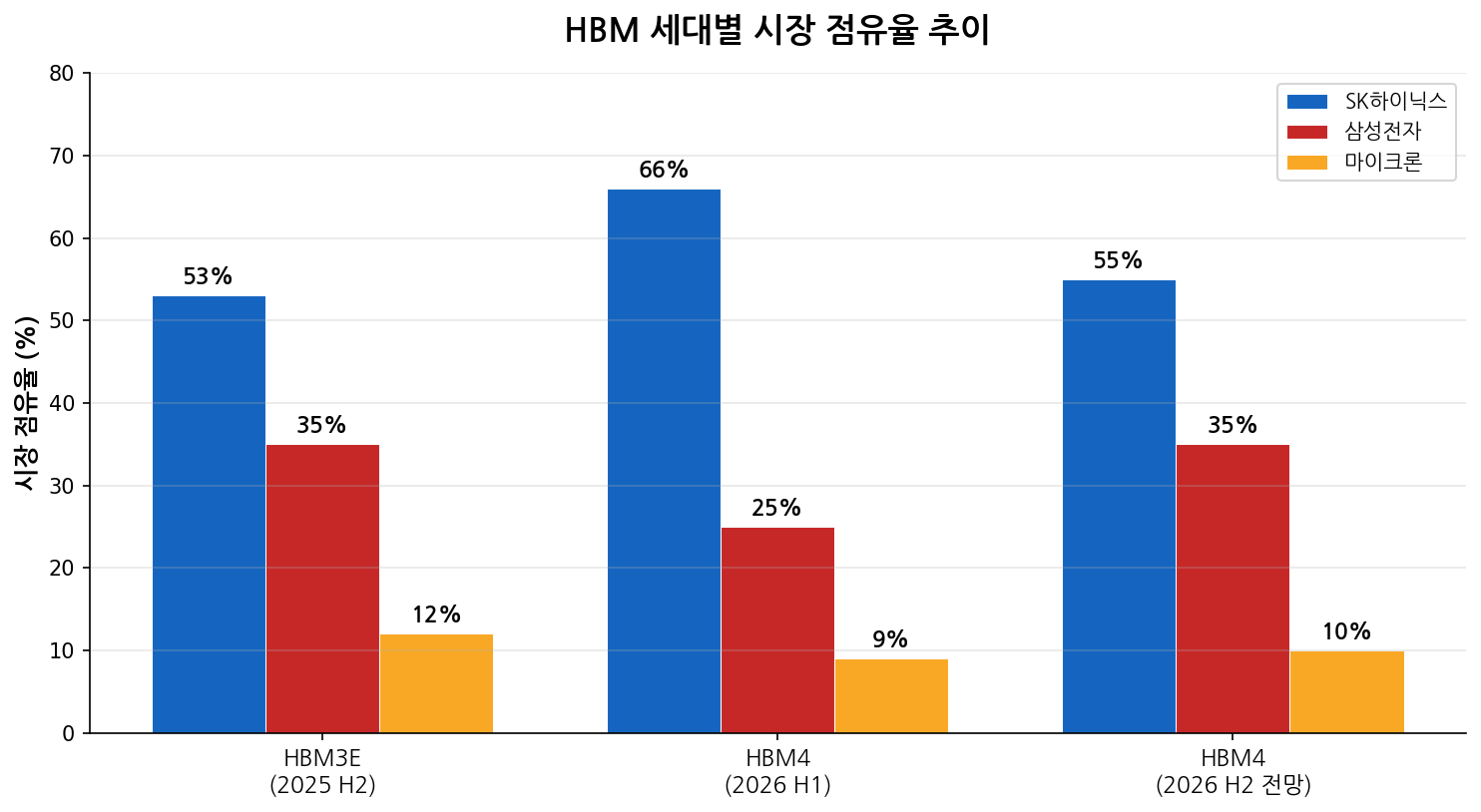
HBM 세대별 시장 점유율 추이 (출처: UBS, TrendForce 종합)
현재 HBM 시장의 압도적 강자는 SK하이닉스입니다. HBM4 초기 물량에서 엔비디아 공급의 약 66%, 즉 3분의 2를 독점하고 있습니다. SK하이닉스는 올 3월 세계 최초로 엔비디아에 HBM4 12단 샘플 공급을 완료했고, 하반기 본격 양산에 돌입합니다.
하지만 삼성전자의 추격도 만만치 않습니다. 삼성은 엔비디아 '베라 루빈'용 HBM4 최종 검증을 통과했고, 핀당 전송속도 11.7Gbps로 엔비디아 요구 기준(10~11Gbps)을 오히려 웃돌았습니다. HBM3E 점유율도 2025년 2분기 17%에서 3분기 35%로 급등하며 빠르게 격차를 좁히고 있습니다.
양사의 HBM4 기술 접근법은 근본적으로 다릅니다. 이 차이를 이해하면 향후 시장 판도를 예측하는 데 큰 도움이 됩니다.
D램 공정의 차이. SK하이닉스는 검증된 10나노급 5세대(1b) D램 공정을 채택했습니다. 이미 HBM3E에서 양산 안정성이 입증된 공정을 기반으로, 수율 리스크를 최소화하면서 물량 공급에 집중하는 전략입니다. 반면 삼성전자는 업계 최초로 최신 6세대(1c) D램 공정을 HBM4에 적용하는 공격적인 승부수를 던졌습니다. 1c 공정은 셀 면적이 더 작아 같은 웨이퍼에서 더 많은 칩을 생산할 수 있고, 전력 소모도 줄어듭니다. 다만 초기 수율 확보가 관건입니다.
로직 베이스다이 전략의 차이. HBM4의 가장 큰 변화인 로직 베이스다이 제조에서도 양사의 전략은 갈립니다. SK하이닉스는 TSMC와 협력하여 베이스다이를 외주 생산합니다. TSMC의 12nm급(12FFC+) 및 5nm급(N5) 로직 공정을 활용해 고성능 로직다이를 확보하는 전략입니다. 삼성전자는 자사 파운드리의 4nm 공정으로 베이스다이를 자체 제작합니다. D램부터 로직다이, 패키징까지 수직 계열화를 통해 원가 경쟁력과 공급 독립성을 확보하겠다는 계산입니다. 나아가 삼성은 차세대 HBM4E에는 2nm 공정 베이스다이 도입도 예고했습니다.
패키징 기술의 차이. SK하이닉스의 핵심 무기는 자체 개발한 '어드밴스드 MR-MUF(Mass Reflow-Molded Underfill)' 공정입니다. 이 기술은 기존 대비 40% 얇은 칩을 적층할 때 휨(warpage) 현상을 정밀하게 제어하여, JEDEC 표준인 775마이크로미터 높이 안에 최대 16단까지 안정적으로 쌓을 수 있게 합니다. 삼성전자는 TC-NCF(Thermo-Compression Non-Conductive Film) 공정을 기반으로 하되, HBM4에서는 하이브리드 본딩 기술 적용을 준비 중입니다. 이 기술이 안착되면 TSV 간격을 크게 줄여 더 많은 데이터 경로를 확보할 수 있습니다.
성능 수치 비교. SK하이닉스의 HBM4는 JEDEC 표준 속도인 8Gbps를 넘어 10Gbps 이상을 달성했으며, 안정적인 양산 수율을 강점으로 내세우고 있습니다. 삼성의 HBM4는 핀당 11.7Gbps로 JEDEC 기준을 46% 초과하며, 스택당 최대 대역폭 3.3TB/s를 구현해 절대 성능에서 앞서고 있습니다. 다만 업계에서는 "속도만 빠르다고 끝이 아니라, 양산 안정성과 공급 물량이 최종 승자를 결정한다"는 시각이 지배적입니다.
■ 70조 투자 전쟁의 내막
2026년 삼성전자와 SK하이닉스의 합산 설비투자 규모는 70조원을 넘어섭니다. 단순히 돈을 많이 쓰는 게 아닙니다. 이 투자의 핵심은 '속도'입니다.
| 2026년 Capex | 약 40조원 | 약 30조원 |
| HBM 월 생산량 | 17만장 → 20만장 | 비공개 (업계 1위) |
| 2026 영업이익 전망 | 133조 4,000억원 | 99조원 |
| HBM4 퍼스트 벤더 | 검증 통과 (2순위) | 세계 최초 샘플 공급 |
| 핵심 전략 | P4-4 조기 준공 + ASIC향 확대 | HBM4 12단 → 16단 로드맵 |
삼성전자는 평택 P4-4 구역 준공 시점을 2027년에서 2026년 1분기로 앞당기며 속도전에 나섰습니다. SK하이닉스는 검증된 기술력과 엔비디아와의 굳건한 파트너십을 무기로 1위 자리를 지키겠다는 전략입니다.
노무라증권은 양사의 2026년 합산 영업이익을 232조원으로 추정했습니다. 메모리 슈퍼사이클이 최소 2027년까지 지속될 것이라는 분석입니다.
■ GTC 2026에서 주목할 포인트
3월 16~19일 산호세에서 열리는 엔비디아 GTC 2026은 HBM4 전쟁의 분수령이 될 행사입니다. 주목해야 할 포인트는 세 가지입니다.

GTC 2026 핵심 체크포인트
첫째, 루빈 플랫폼의 상세 사양 공개입니다. HBM4를 몇 개 탑재하는지, 용량은 얼마인지에 따라 삼성과 SK하이닉스의 수혜 규모가 달라집니다.
둘째, HBM4 공급사 배분 비율입니다. 현재 SK하이닉스 66%, 삼성 25%, 마이크론 9%로 알려진 비율이 GTC에서 조정될 가능성이 있습니다. 삼성의 검증 통과로 물량 확대가 예상됩니다.
셋째, '파인만(Feynman)' 아키텍처 힌트입니다. 루빈 다음 세대인 파인만에 대한 로드맵이 공개되면, HBM4E나 HBM5 수요까지 선반영될 수 있습니다.
■ 투자자가 체크해야 할 리스크
장밋빛 전망만 있는 건 아닙니다. 반드시 챙겨야 할 리스크가 있습니다.
첫째, 엔비디아 의존도 리스크. 현재 HBM 수요의 80% 이상이 엔비디아에서 나옵니다. 엔비디아의 실적이 꺾이면 HBM 시장 전체가 흔들릴 수 있습니다. 실제로 엔비디아의 950억 달러 규모 공급망에 대해 'AI 버블' 우려가 제기되고 있습니다.
둘째, ASIC 칩의 부상. 구글 TPU, 아마존 트레이니움 등 자체 AI 칩을 개발하는 빅테크 기업들이 늘고 있습니다. 이들의 ASIC 칩에도 HBM이 필요하긴 하지만, 엔비디아 GPU 독점 구도가 약화되면 수요 구조가 바뀔 수 있습니다.
셋째, 지정학적 변수. 미국의 대중국 반도체 수출 규제가 강화되고, 미중 기술 패권 경쟁이 격화되는 상황에서 한국 반도체 기업들의 판매처가 제한될 가능성이 있습니다.
■ 마무리: 누구의 편에 설 것인가
정리하겠습니다. HBM4 전쟁은 단순한 기술 경쟁이 아닙니다. AI 시대의 핵심 인프라를 누가 장악하느냐의 문제입니다.
SK하이닉스는 검증된 1위로서 HBM4 시장의 3분의 2를 선점했습니다. 삼성전자는 빠른 추격으로 격차를 좁히며 2026년 하반기 반전을 노리고 있습니다. 양사의 합산 영업이익이 232조원에 달할 것이라는 전망은, 이 전쟁에서 궁극적으로 두 회사 모두 승자가 될 수 있음을 시사합니다.
3월 16일 GTC 2026. 엔비디아 젠슨 황의 입에서 나올 '루빈'의 구체적 사양이 이 전쟁의 다음 국면을 결정할 겁니다. 투자자라면 그날의 키노트를 반드시 챙기세요.
※ 본 글은 투자 권유가 아닌 정보 제공 목적으로 작성되었습니다. 투자 판단은 본인의 책임 하에 이루어져야 합니다.
'투자' 카테고리의 다른 글
| FIRE족 경제적 자유 현실 로드맵: 한국에서 조기 은퇴하려면 얼마가 필요한가 (0) | 2026.03.19 |
|---|---|
| 2026 금값 전망과 금투자 방법 완전 정리: 초보자가 지금 시작해도 되는 이유 (1) | 2026.03.19 |
| 삼성전자 노조 5월 총파업 예고: 8만 9천명 찬반투표 돌입, OPI 성과급 상한 폐지 논란과 주가 영향 총정리 (0) | 2026.03.10 |
| 코스피 역대급 대반전: 하루 만에 9.63% 폭등, 2008년 이후 최고 반등의 비밀 (1) | 2026.03.05 |
| 비트코인 50% 폭락, 공포탐욕지수 10: 2026 암호화폐 대붕괴의 진실과 반등 시나리오 (0) | 2026.03.05 |